说明:这是我在学习Stanford CS336(2025版)课程时整理的 Tokenization 笔记,主要依据课程讲义与课堂内容,并加入了我自己的理解与例子。内容涵盖 tokenizer 的基本概念、vocabulary size、character/byte/word 三种朴素分词方案的优缺点,以及 BPE(Byte Pair Encoding)的核心思路与动机。
tokenization(分词)
把原始文本(Unicode 字符串)切分并编码成 tokens / token IDs 的过程。
- Tokenization = 将 Unicode 字符串通过 tokenizer encode 成 token 序列(通常是整数 ID)
- 并且支持 decode 把 ID 序列还原为字符串。
Tokenizer 提供:
- encode: string -> token IDs (整数, 比如 15496, 11, 995, 0)
- decode: token IDs -> string (字符串)
Vocabulary size(词表大小)
就是Tokenizer 允许使用的“token 种类”的总数,也等价于 token ID 的取值范围大小。 更具体的说:
- Tokenizer 会维护一张“词表”(vocabulary):
token(文本片段) ↔ token ID(整数编号) 的映射表。 - Vocabulary size就是这张表里一共有多少个条目(多少个不同 token)。
- 因为每个 token 都对应一个唯一的整数 ID,所以也可以理解为:
一共有多少个可用的 token ID(通常 ID 从 0 到 vocab_size-1)。
举个极简例子
假设词表里只有 5 个 token:
| token(片段) | token ID |
|---|---|
<pad> | 0 |
<eos> | 1 |
你 | 2 |
好 | 3 |
Hello | 4 |
那 vocabulary size = 5。
模型输入的每个 token 就只能是这 5 个 ID 之一(0~4)。
注意
- 词表越大:token 种类更丰富,可能更“细致”,但模型的输入/输出层(embedding、输出 softmax)也会更大、更耗资源。
- 词表越小:更省,但同样一句话可能会被拆成更多 token。
Tokenizer
下面举个例子来说明分词器的工作原理:
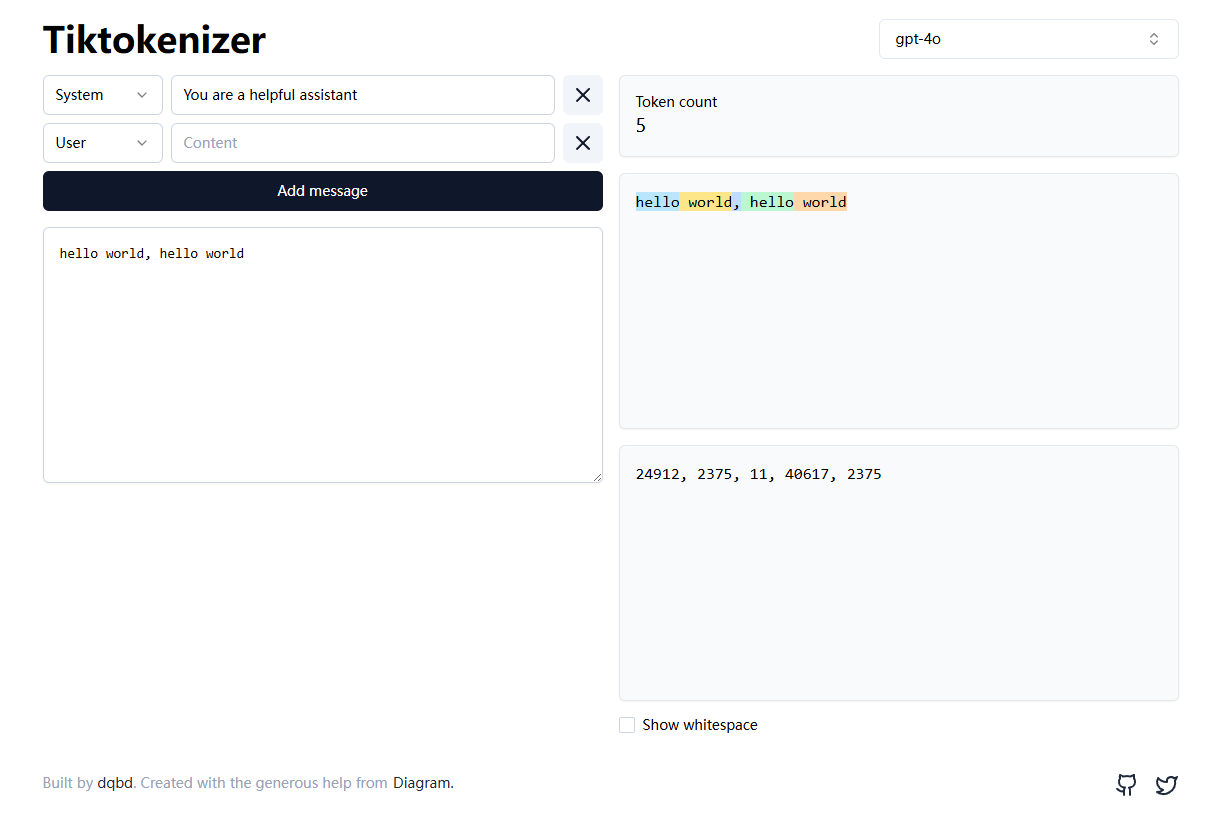 在这个网页我选择了gpt-4o的tokenizer, 然后输入
在这个网页我选择了gpt-4o的tokenizer, 然后输入hello world, hello world, 在右侧可以看到输入文本会被 encode 成一串 token(片段)以及对应的 token IDs(整数), 这里用不同颜色表示了分词的过程, 并在下方显示了整数
要注意的是:
- Tokenizer 的编码通常是可逆的:
decode(encode(text)) ≈ text,因此空格、标点、换行等都会被编码表示,不会随意删除,所以空格在这里属于token的一部分, 这与直接消除空格的传统自然语言处理方法不同 hello(前面没有空格)和hello(前面有空格)所映射的整数是不同的- 很多情况下, 一个token的空格在前面而不是后面
如果你想实现tokenization(分词), 最简单的方法是什么?
Character-based tokenization(基于字符的分词)
一个Unicode字符串是一系列的的Unicode字符, 这样的话我们可以将每个字符转换成整数
#Each character can be converted into a code point (integer) via `ord`.
#每个字符都可以通过"ord"转换成一个代码点(整数)。
assert ord("a") == 97
assert ord("🌍") == 127757
#It can be converted back via `chr`.
#它可以通过`chr'转换回来。
assert chr(97) == "a"
assert chr(127757) == "🌍"
但是这种方式存在问题:
- vocabulary(词表)非常大
- 每个字符都被分配了对应的整数, 这是平均的, 但是有的字符出现的频率远高于其他字符, 例如
🌍, 这样就导致词表被低效地(inefficiently)使用
Byte-based tokenization(基于字节的分词)
Unicode字符串可以被表示成一系列的字节, 这样的话我们可以将字节转化为整数
理解时出现的误区
像a,b,c, 这些字符不都是一个字节(1byte)吗, 为什么说编译成字节后还能被编码成不同的整数, 是如何做到区分的?
- 一个 byte 既是“大小单位”,也是“能存一个 0~255 的数”
- 1 byte = 8 bit
- 8 bit 一共有 (2^8 = 256) 种组合
- 所以一个 byte 能表示一个整数:0~255
#Some Unicode characters are represented by one byte:
assert bytes("a", encoding="utf-8") == b"a"
#Others take multiple bytes:
assert bytes("🌍", encoding="utf-8") == b"\xf0\x9f\x8c\x8d"
有些字符只需要一个字节表示, 而有些字符需要多个字节表示
优点
- 由于一个字节表示的整数范围是0~255, 所以Byte-based tokenization的vocabulary就是256的大小, 这非常小
- 各个字节被用到的概率差不多, 所以遇到的稀疏性问题并不多
存在的问题
这种方式存在很长的序列, 并且compression_ratio(压缩比, 这里用的是字节数 / token 数) 等于1 由于transformer的上下文长度有限, 即一次能处理的token数有限, 所以token数太多就会导致推理/训练更慢更贵 transformer的注意力计算的复杂度大致是O(n^2), token 序列越长,计算量增长很快(二次方)
补充知识
1) Transformer 是什么
Transformer = 多层堆叠的模块,每层主要有两块:
- Self-Attention(自注意力):让每个 token 去看其它 token,决定“我该关注谁”
- FFN/MLP(前馈网络):对每个 token 的向量再做一次非线性变换(相当于“思考加工”)
不断重复很多层后,模型就能做:
- 预测下一个 token(生成)
- 分类、翻译、摘要等(在不同训练方式下)
2) Attention(注意力)到底在干嘛?
直觉一句话:
对当前 token 来说,把其它 token 的信息按“相关程度”加权求和。
比如句子:我把苹果放进了冰箱,因为它很冷。
当模型处理“它”这个 token 时,注意力应该更多指向“冰箱”(而不是“苹果”),因为“很冷”更相关。
关键机制:打分 + 加权平均
对序列里的每个位置 (i)(第 i 个 token),它会:
- 给其它每个 token (j) 算一个“相关性分数” score(i, j)
- 把分数变成权重(softmax,权重加起来=1)
- 用这些权重对其它 token 的信息做加权平均,得到新的表示
所以 attention 像是“在整段话里做检索/对齐”。
3) 为什么说 attention 是“平方级”(quadratic)?
假设一段输入有 (n) 个 token。
- 对每个 token (i),都要去跟所有 token (j) 计算一次相关性
- 一共有 (n) 个 (i),每个要看 (n) 个 (j)
- 所以计算/存储规模大约是 (n \times n = n^2) 可以简单理解成遍历所有token, 然后每个token都和其他所有token进项相关性计算,所以是平方级 因此 token 越多,attention 计算就会很快变得很贵。
Word-based tokenization
将字符串分成一个单词(word), 再将不同的单词转换为整数
存在的问题
- 词的数量巨大, 我们不知道到底有多少词
- 一些罕见的词导致模型学不到东西, 单独给它一个token其实很浪费
- 词表大小不固定, 如果词表定义为"训练数据里出现过的所有词", 那词表的大小会随数据变化
- 训练没见过的新词只能变成UNK(unknown), 这会让模型丢失信息,还会把评测(perplexity)搞得不靠谱,因为不同 tokenizer 的
<UNK>策略会影响概率计算
Byte Pair Encoding (BPE, 字节对编码)
基本思想
不先入为主的去分割raw text , 而是让用原文训练模型
方法
- 先将字符串转化为一系列字节, 就像Byte-based tokenization
- 然后统计相邻token对的出现频率, 找到出现次数最多的那一对
- 将这一对合并成新的token, 用新的token替换原来所有出现的位置
[h][e]→[he]
- 再回到第一步循环
效果
- 常见片段会被合并成更长的 token(序列变短,压缩更好)
- 罕见片段不会被合并太多,仍然用多个小 token 表示(但依然可表示)
总结
1) Tokenizer 是什么
- Tokenizer 的作用:在 字符串(string) 和 tokens(通常是整数 IDs / indices) 之间做双向转换
- encode:string → token IDs
- decode:token IDs → string
- 语言模型实际处理的是 token ID 序列(不是直接处理字符)。
2) 三种“朴素”分词方式的问题(suboptimal)
- Character-based(按字符)
- 优点:简单、覆盖所有字符
- 缺点:token 序列很长,效率低
- Byte-based(按字节,纯 byte-level)
- 优点:词表固定且很小(256),永远不会 OOV/UNK
- 缺点:压缩比差(≈1),token 数几乎等于字节数,序列太长;而 attention 复杂度约 (O(n^2))
- Word-based(按词)
- 优点:序列相对短
- 缺点:词表可能巨大、罕见词很多、遇到新词会出现 UNK,还不容易给出固定 vocab size
3) BPE(Byte Pair Encoding,字节对编码)为什么有效
- 核心直觉:用语料统计自动学习词表
- 常见的片段/子词 → 合并成一个 token
- 罕见的片段 → 仍用多个 token 表示
- 训练过程(概念):从最小单位开始(常见做法是从 bytes),不断合并最常见的相邻 token 对,逐步形成子词词表。
- 结果:兼顾
- 覆盖面(几乎不需要 UNK)
- 序列长度(比纯 byte-level 短)
- 词表大小可控(比纯 word-level 更稳定)